Сравнение плана и факта достаточно частая задача в бизнес-среде.
Рассмотрим различные виды план-факт анализа в Excel и способы их создания.
Наиболее популярными видами сравнения являются таблицы и диаграммы.
Таблицы удобно использовать, если сравнение между планом и фактом происходит по различным показателям, например, данные по продажам различных товаров компании, P&L, CF и т.д.
Диаграммы удобнее для визуализации план-факта конкретного показателя, например, месячная динамика продаж конкретного товара.
Стандартная план-факт таблица состоит из нескольких блоков: в левой части — название показателя, в центре — данные с планом и фактом, в правой — отклонение (в абсолютных величинах, в процентах).
Для лучшей визуализации дополнительно можно окрашивать ячейку или шрифт текста с отклонением, например, в красный и зеленый цвета.
Предположим, что для план-факт графика у нас имеются помесячные данные по продажам (фактические и планируемые), а также отклонение между фактом и планом:
Разберем 2 различных варианта построения план-факт диаграмм.
Выделяем диапазон ячеек A1:M4 и добавляем стандартный график с маркерами (на панели вкладок выбираем Вставка -> График -> График с маркерами):
На графике отобразились 3 ряда — Факт, План и Отклонение, при этом ряд с отклонением получился существенно ниже первых двух за счет эффекта масштаба.
Поэтому сделаем ряд «Отклонение» гистограммой (нажимаем правой кнопкой мыши на ряд, выбираем Изменить тип диаграммы -> Гистограмма -> Гистограмма с группировкой) и перенесем его на вспомогательную ось (снова выбираем ряд, нажимаем правую кнопку и выбираем Формат ряда данных -> Параметры ряда -> По вспомогательной оси)
Теперь приведем в порядок внешний вид план-факт диаграммы — скроем вспомогательную ось, установим минимальные и максимальные значение для основной и вспомогательной оси:
Добавляя подпись данных к рядам получаем окончательный вид план-факт графика:
Еще одним вариантом план-факт анализа является диаграмма с использованием свойств полосы повышения-понижения.
Повторяем действия из первого примера, выделяем диапазон ячеек A1:M3 (без отклонения) и строим график с маркерами:
Во вкладке Конструктор (Excel 2013 и старше) или Макет (Excel 2007-2010) добавляем Полосы повышения-понижения:
Между линией факта и плана появились прямоугольные полосы (полосы повышения-понижения), которые показывают изменение между линиями.
При этом в зависимости от знака отклонения они окрашиваются в разные цвета (в данном примере, если факт больше плана, то в черный и наоборот, если факт меньше плана, то в белый).
Изменим цвет полосы повышения на зеленый, а полосы понижения на красный, а также сделаем их полупрозрачными, чтобы полосы не наезжали на линии графика (нажимаем правой кнопкой мыши на полосу и выбираем Формат полос повышения/понижения):
Подробно ознакомиться с шаблонами диаграмм из разобранных примеров — скачать пример.
источник
Следующий пример основан на вымышленных данных, относящихся к изучению удовлетворенности жизнью. Предположим, что вопросник был направлен 100 случайно выбранным взрослым. Вопросник содержал 10 пунктов, предназначенных для определения удовлетворенности на работе, удовлетворенности своим хобби, удовлетворенностью домашней жизнью и общей удовлетворенностью в других областях жизни. Ответы на вопросы были введены в компьютер и промасштабированы таким образом, чтобы среднее для всех пунктов стало равным приблизительно 100.
Просто оцените распределение ответа для выполнения имитаций Монте-Карло. Используйте платформу надежности. Настройте распределение выживаемости, чтобы настроить и сравнить различные дистрибутивы. Предотвращение отказов и повышение качества гарантий — все это причины использовать проверенные методы, чтобы в полной мере понять эффективность ваших продуктов в долгосрочной перспективе.
Хотите узнать, как лучше всего распространять информацию о точном прогнозе надежности ваших продуктов и компонентов? Например, анализ распределения выживания позволяет указать непараметрическое распределение и количество параметрических распределений и визуально сравнить настройки.
Результаты были помещены в файл данных Factor.sta. Открыть этот файл можно с помощью опции Файл — Открыть; наиболее вероятно, что этот файл данных находится в директории /Examples/Datasets. Ниже приводится распечатка переменных этого файла (для получения списка выберите Все спецификации переменных в меню Данные).
Цель анализа . Целью анализа является изучение соотношений между удовлетворенностью в различных сферах деятельности. В частности, желательно изучить вопрос о числе факторов, «скрывающихся» за различными областями деятельности и их значимость.
Быстрое определение данных процесса через интерфейс перетаскивания и гибкость генератора карт управления. Создание графических представлений естественных группировок для выделения конфигураций и решения проблем. Платформа анализа измерительной системы поддерживает несколько методов анализа, включая оценку процесса измерения Дональда Дж. Вы можете легко визуализировать источники изменений в ваших измерительных процессах, оценить дефекты продуктов и контролировать стабильность процесса.
Вы предоставляете данные и параметры, необходимые для каждого сканирования, и утилита использует соответствующие макрофункции для вычисления и отображения результатов в таблице. В дополнение к таблицам результатов некоторые инструменты генерируют графики. Функции анализа данных могут использоваться на одном листе за раз. Когда вы анализируете данные на больших электронных таблицах, результаты отображаются на первом листе, а пустые таблицы с форматированием отображаются в других. Чтобы проанализировать данные в других таблицах, повторно запустите инструмент анализа для каждого рабочего листа.
Выбор анализа. Выберите Факторный анализ в меню Анализ — Многомерный разведочный анализ для отображения стартовой панели модуля Факторный анализ. Нажмите на кнопку Переменные на стартовой панели (см. ниже) и выберите все 10 переменных в этом файле.
Используемый инструмент зависит от количества факторов и количества образцов, извлеченных из популяций, подлежащих тестированию. Этот инструмент позволяет провести простой анализ дисперсии данных нескольких образцов. Анализ проверяет гипотезу о том, что каждый образец исходит из одного и того же основного распределения вероятности по отношению к альтернативной гипотезе о том, что лежащие в основе распределения вероятности не одинаковы для всех выборок.
Анова: два фактора с репликацией. Этот инструмент анализа подходит, когда можно классифицировать данные в соответствии с двумя разными размерами. Представьте себе исследование по высоте растений с различными марками удобрений и которые хранятся при разных температурах. Для каждой пары (удобрения, температура) для высоты растений получено равное количество наблюдений.
Другие опции . Для выполнения стандартного факторного анализа в этом диалоговом окне имеется все необходимое. Для получения краткого обзора других команд, доступных из стартовой панели, вы можете выбрать в качестве входного файла корреляционную матрицу (используя поле Файл данных). В поле Удаление ПД вы можете выбрать построчное или попарное исключение или подстановка среднего для пропущенных данных.
Растения, высота которых измеряется для различных марок удобрений, поступают из одного и того же основного населения. Растения, высота которых измеряется с разными уровнями температуры, исходят от одной и той же основной популяции.
- В этом анализе температура не учитывается.
- Маркировка удобрений в этот анализ не включена.
Принимая во внимание влияние различий между отмеченными в первой точке знаками удобрений и различиями температуры, отмеченными во второй точке, шесть образцов, представляющих все пары значений (удобрения, температура), поступают из одной и той же популяции.
Задайте метод выделения факторов. Нажмем теперь кнопку OK для перехода к следующему диалоговому окну с названием Задайте метод выделения факторов. С помощью этого окна диалога вы сможете просмотреть описательные статистики, выполнить множественный регрессионный анализ, выбрать метод выделения факторов, выбрать максимальное число факторов, минимальные собственные значения, а также другие действия, относящиеся к специфике методов выделения факторов. А теперь перейдем во вкладку Описательные.
Альтернативная гипотеза состоит в том, чтобы предположить, что есть эффекты, связанные с определенными парами (удобрениями, температурами) за пределами различий, которые связаны только с удобрением или только с температурой. Анова: два фактора без репликации.
Этот инструмент анализа полезен, когда данные классифицируются в соответствии с двумя различными измерениями, как в случае двухфакторного теста с репликацией. Однако использование этого инструмента предполагает одно наблюдение для каждой пары. Коэффициент корреляции, как и ковариация, позволяет узнать, до какой степени две числовые переменные «меняются вместе».
Просмотр описательных статистик. Теперь нажмите на кнопку Просмотреть корр./средние/ст.откл. в этом окне для того, чтобы открыть окно Просмотр описательных статистик.
Эти два инструмента предоставляют таблицу результатов, матрицу, которая соответственно показывает коэффициент корреляции или ковариацию между каждой парой числовых переменных. Разница между этими двумя инструментами связана с тем, что коэффициенты корреляции находятся в шахматном порядке между -1 и 1 включительно. Ковариации не пошатнулись.
Коэффициент корреляции и ковариация показывают, насколько две переменные «меняются вместе». Средство статистического анализа генерирует одномерный статистический отчет из данных диапазона ввода и предоставляет информацию о центральном тренде и изменчивости данных.
Теперь вы можете рассмотреть описательные статистики графически или с помощью таблиц результатов.
Вычисление корреляционной матрицы. Нажмите на кнопку Корреляции во вкладке Дополнительно для того, чтобы отобразить таблицу результатов с корреляциями.
Инструмент анализа экспоненциального сглаживания. Инструмент анализа экспоненциального сглаживания вычисляет значение, основанное на предсказании, установленном для предыдущего периода. Это значение корректируется в соответствии с ошибкой этого предыдущего прогноза.
Константы сглаживания обычно принимают значения от 0, 2 до 0. Эти значения показывают, что прогноз должен быть скорректирован до 20 или 30 процентов для предыдущей ошибки прогноза. Более высокие константные значения приводят к более быстрым ответам, но могут генерировать противоречивые прогнозы.
Все корреляции в этой таблице результатов положительны, а некоторые корреляции имеют значительную величину. Например, переменные Hobby_1 и Miscel_1 коррелированны на уровне 0.90. Некоторые корреляции (например, корреляции между удовлетворенностью на работе и удовлетворенностью дома) кажутся сравнительно малыми. Это выглядит так, как будто матрица имеет некоторую отчетливую структуру.
Более низкие константы могут привести к значительным задержкам в прогнозируемых значениях. Этот инструмент позволяет проверить нулевую гипотезу о том, что эти два образца взяты из распределений с равными дисперсиями и альтернативной гипотезой о том, что отклонения не равны в базовых дистрибутивах. Инструмент анализа Фурье решает проблемы в линейных системах и анализирует данные с помощью «Быстрого преобразования Фурье» для преобразования данных. Этот инструмент также допускает обратные преобразования, в которых обратный преобразованным данным возвращает исходные данные.
Метод выделения. Теперь нажмем кнопку Отмена в диалоговом окне Просмотр описательных статистик для того, чтобы вернуться в диалоговое окно Задайте метод выделения факторов. Вы можете сделать выбор из нескольких методов выделения во вкладке Дополнительно (см. вкладку Дополнительно диалогового окна Задайте метод выделения факторов для описания каждого метода, а также Вводный обзор с описанием метода Главных компонент и метода Главных факторов). В этом примере по умолчанию принимается метод Главных компонент, поле Макс. число факторов содержит значение 10 (максимальное число факторов в этом примере) и поле Мин. собств. значение содержит 0 (минимальное значение для этой команды).
Анализатор гистограммы вычисляет индивидуальную и кумулятивную частоты для диапазона ячеек данных и местоположений данных. Этот инструмент генерирует данные для ряда вхождений значения в наборе данных. Например, в классе из 20 учеников вы можете определить распределение заметок в алфавитном порядке. Гистограмма показывает терминалы и количество нот между нижней и текущей границами. Наиболее общий одиночный балл представляет собой режим данных.
Средство мобильного усреднения используется для прогнозирования значений за период прогнозирования на основе среднего значения переменной за определенное количество предыдущих периодов. Скользящее среднее обеспечивает информацию о тренде, которая представляет собой простую среднюю маску исторических данных. Используйте этот инструмент для определения прогнозов продаж, например, управления запасами.
Для продолжения анализа нажмите кнопку OK.
Просмотр результатов. Вы можете просмотреть результаты факторного анализа в окне диалога Результаты факторного анализа. Сначала выберите вкладку Объясненная дисперсия.
Генератор случайных чисел. Инструмент анализа генератора случайных чисел завершает серию с независимыми случайными числами, которые поступают из распределения. Вы можете охарактеризовать субъекты популяции с распределением вероятностей. Например, вы можете использовать нормальный закон распределения, чтобы охарактеризовать популяцию отдельных размеров, или использовать распределение Бернулли двух возможных результатов, чтобы охарактеризовать популяцию результатов броска монет.
Средство анализа строки и процентности генерирует таблицу, содержащую ранг каждого значения в наборе данных. Вы можете проанализировать относительный рейтинг значений в наборе данных. Инструмент «Регрессия» выполняет линейный регрессионный анализ, используя метод наименьших квадратов, чтобы найти линию из наблюдаемых значений. Вы можете разделить доли, которые каждый из этих трех факторов представляет в производительности, на основе набора данных о производительности, а затем использовать результаты для прогнозирования эффективности нового спортсмена, который еще не был протестирован, нет теста.
Отображение собственных значений . Назначение собственных значений и их полезность для пользователя при принятии решения о том, сколько следует оставить факторов (интерпретировать) были описаны в Вводном обзоре. Теперь нажмем на кнопку Собственные значения, чтобы получить таблицу с собственными значениями, процентом общей дисперсии, накопленными собственными значениями и накопленными процентами.
Если население слишком велико для обработки или представления графически, вы можете использовать репрезентативную выборку. Вы также можете создать образец, который содержит только значения определенного цикла, если вы считаете, что данные являются периодическими.
Например, если в серии данных содержатся квартальные показатели продаж, создается образец из периодичности, равный четырем местам, для значений в том же квартале в полученной серии. Три инструментария для трех разных предположений: дисперсии населения равны, дисперсии населения не равны, данные двух образцов — данные, наблюдаемые до лечения и после лечения по тем же предметам. Этот тест не предполагает, что дисперсии двух популяций равны. Среди результатов, созданных этим инструментом, является кумулятивная дисперсия, совокупная мера распределения данных по среднему значению, которая получается из следующей формулы.
Как видно из таблицы, собственное значение для первого фактора равно 6.118369; т.е. доля дисперсии, объясненная первым фактором равна приблизительно 61.2%. Заметим, что эти значения случайно оказались здесь легко сравнимыми, так как анализу подвергаются 10 переменных, и поэтому сумма всех собственных значений оказывается равной 10. Второй фактор включает в себя около 18% дисперсии. Остальные факторы содержат не более 5% общей дисперсии. Выбор числа факторов. В разделе Вводный обзор кратко описан способ, как полученные собственные значения можно использовать для решения вопроса о том, сколько факторов следует оставить в модели. В соответствии с критерием Кайзера (Kaiser, 1960), вы должны оставить факторы с собственными значениями большими 1. Из приведенной выше таблицы следует, что критерий приводит к выбору двух факторов.
Для этого теста предполагается, что оба набора данных поступают из распределений с одинаковыми дисперсиями. Мы говорим о гомосексуальном испытании. Для этого теста предполагается, что оба набора данных поступают из распределений с неравными отклонениями. Мы говорим о гетероскедастическом тесте. Используйте этот тест, если объекты двух образцов различны. Используйте сравниваемый образец теста, описанный в следующем примере для группы идентичных субъектов, и если измерения, проведенные для обоих образцов, до и после лечения для каждого испытуемого.
Критерий каменистой осыпи . Теперь нажмите на кнопку График каменистой осыпи, чтобы получить график собственных значений с целью применения критерия осыпи Кэттеля (Cattell, 1966). График, представленный ниже, был дополнен отрезками, соединяющими соседние собственные значения, чтобы сделать критерий более наглядным. Кэттель (Cattell) утверждает, основываясь на методе Монте-Карло, что точка, где непрерывное падение собственных значений замедляется и после которой уровень остальных собственных значений отражает только случайный «шум». На графике, приведенном ниже, эта точка может соответствовать фактору 2 или 3 (как показано стрелками). Поэтому испытайте оба решения и посмотрите, которое из них дает более адекватную картину.
Для вычисления степени свободы используется следующая формула. Этот инструмент используется для проверки нулевой гипотезы о том, что нет никакой разницы между двумя средними населения по отношению к однонаправленной или двунаправленной альтернативной гипотезе. Этот компонент включает инструменты, которые анализируют данные и параметры, а также используя соответствующие статистические или инженерные макрофункции, вычисляет и отображает результаты в выходной таблице.
В дополнение к выходным таблицам некоторые из этих инструментов представляют результаты диаграммы. Функции анализа данных могут использоваться только на листе за один раз. При выполнении анализа данных в группах рабочих листов результаты будут отображаться на первом листе, а на других листах будут отображаться пустые форматированные таблицы. Чтобы проанализировать данные оставшихся листов, снова используйте инструмент анализа для каждого из них.
Теперь рассмотрим факторные нагрузки.
Факторные нагрузки . Как было описано в разделе Вводный обзор, факторные нагрузки можно интерпретировать как корреляции между факторами и переменными. Поэтому они представляют наиболее важную информацию, на которой основывается интерпретация факторов. Сначала посмотрим на (неповернутые) факторные нагрузки для всех десяти факторов. Во вкладке Нагрузки диалогового окна Результаты факторного анализа в поле Вращение факторов зададим значение без вращения и нажмем на кнопку Факторные нагрузки для отображения таблицы нагрузок.
Вспомним, что выделение факторов происходило таким образом, что последующие факторы включали в себя все меньшую и меньшую дисперсию (см. раздел Вводный обзор). Поэтому не удивительно, что первый фактор имеет наивысшую нагрузку. Отметим, что знаки факторных нагрузок имеют значение лишь для того, чтобы показать, что переменные с противоположными нагрузками на один и тот же фактор взаимодействуют с этим фактором противоположным образом. Однако вы можете умножить все нагрузки в столбце на -1 и обратить знаки. Во всем остальном результаты окажутся неизменными.
Вращение факторного решения. Как описано в разделе Вводный обзор, действительная ориентация факторов в факторном пространстве произвольна, и всякое вращение факторов воспроизводит корреляции так же хорошо, как и другие вращения. Следовательно, кажется естественным повернуть факторы таким образом, чтобы выбрать простейшую для интерпретации факторную структуру. Фактически, термин простая структура был придуман и определен Терстоуном (Thurstone, 1947) главным образом для описания условий, когда факторы отмечены высокими нагрузками на некоторые переменные и низкими — для других, а также когда имеются несколько больших перекрестных нагрузок, т.е. имеется несколько переменных с существенными нагрузками на более чем один фактор. Наиболее стандартными вычислительными методами вращения для получения простой структуры является метод вращения варимакс, предложенный Кайзером (Kaiser, 1958). Другими методами, предложенными Харманом (Harman, 1967), являются методы квартимакс, биквартимакс и эквимакс (см. Harman, 1967).
Выбор вращения . Сначала рассмотрим количество факторов, которое вы желаете оставить для вращения и интерпретации. Ранее было решено, что наиболее правдоподобным и приемлемым числом факторов является два, однако на основе критерия осыпи было решено учитывать также и решение с тремя факторами. Нажмите на кнопку Отмена для того, чтобы возвратиться в окно диалога Задайте метод выделения факторов, и измените поле Максимальное число факторов во вкладке Быстрый с 10 на 3, затем нажмите кнопку OK для того, чтобы продолжить анализ.
Теперь выполним вращение по методу варимакс. Во вкладке Нагрузки диалогового окна Результаты факторного анализа в поле Вращение факторов установите значение Варимакс исходных.
Нажмем кнопку Факторные нагрузки для отображения в таблице результатов получаемых факторных нагрузок.
Отображение решения при вращении трех факторов. В таблице приведены существенные нагрузки на первый фактор для всех переменных, кроме относящихся к дому. Фактор 2 имеет довольно значительные нагрузки для всех переменных, кроме переменных связанных с удовлетворенностью на работе. Фактор 3 имеет только одну значительную нагрузку для переменной Home_1. Тот факт, что на третий фактор оказывает высокую нагрузку только одна переменная, наводит на мысль, а не может ли получиться такой же хороший результат без третьего фактора?
Обозрение решения при вращении двух факторов . Снова нажмите на кнопку Отмена в окне диалога Результаты факторного анализа для того, чтобы возвратиться к диалоговому окну Задайте метод выделения факторов. Измените поле Максимальное число факторов во вкладке Быстрый с 3 до 2 и нажмите кнопку OK для того, чтобы перейти в диалоговое окно Результаты факторного анализа. Во вкладке Нагрузки в поле Вращение факторов установите значение Варимакс исходных и нажмите кнопку Факторные нагрузки.
Фактор 1, как видно из таблицы, имеет наивысшие нагрузки для переменных, относящихся к удовлетворенности работой. Наименьшие нагрузки он имеет для переменных, относящихся к удовлетворенности домом. Другие нагрузки принимают промежуточные значения. Фактор 2 имеет наивысшие нагрузки для переменных, связанных с удовлетворенностью дома, низшие нагрузки — для удовлетворенности на работе средние нагрузки для остальных переменных.
Интерпретация решения для двухфакторного вращения . Можно ли интерпретировать данную модель? Все выглядит так, как будто два фактора лучше всего идентифицировать как фактор удовлетворения работой (фактор 1) и как фактор удовлетворения домашней жизнью (фактор 2). Удовлетворение своим хобби и различными другими аспектами жизни кажется относящимися к обоим факторам. Эта модель предполагает в некотором смысле, что удовлетворенность работой и домашней жизнью согласно этой выборке могут быть независимыми друг от друга, но оба дают вклад в удовлетворение хобби и другими сторонами жизни.
Диаграмма решения, основанного на вращении двух факторов . Для получения диаграммы рассеяния двух факторов нажмите на кнопку 2М график нагрузок во вкладке Нагрузки диалогового окна Результаты факторного анализа. Диаграмма, показанная ниже, попросту показывает две нагрузки для каждой переменной. Заметим, что диаграмма рассеяния хорошо иллюстрирует два независимых фактора и 4 переменных (Hobby_1, Hobby_2, Miscel_1, Miscel_2) с перекрестными нагрузками.
Теперь посмотрим, насколько хорошо может быть воспроизведена наблюдаемая ковариационная матрица по двухфакторному решению.
Воспроизведенная и остаточная корреляционная матрица. Нажмите на кнопку Воспроизведенные и остаточные корреляции во вкладке Объясненная дисперсия, для того чтобы получить две таблицы с воспроизведенной корреляционной матрицей и матрицей остаточных корреляций (наблюдаемых минус воспроизведенных корреляций).
Входы в таблице Остаточных корреляций могут быть интерпретированы как «сумма» корреляций, за которые не могут отвечать два полученных фактора. Конечно, диагональные элементы матрицы содержат стандартное отклонение, за которое не могут быть ответственны эти факторы и которые равны квадратному корню из единица минус соответствующие общности для двух факторов (вспомним, что общностью переменной является дисперсия, которая может быть объяснена выбранным числом факторов). Если вы тщательно рассмотрите эту матрицу, то сможете увидеть, что здесь фактически не имеется остаточных корреляций, больших 0.1 или меньшие -0.1 (в действительности только малое количество из них близко к этой величине). Добавим к этому, что первые два фактора включают около 79% общей дисперсии (см. накопленный % собственных значений в таблице результатов).
«Секрет» удачного примера . Пример, который вы только что изучили, на самом деле дает решение двухфакторной задачи, близкое к идеальному. Оно определяет большую часть дисперсии, имеет разумную интерпретацию и воспроизводит корреляционную матрицу с умеренными отклонениями (остаточными корреляциями). На самом деле реальные данные редко позволяют получить такое простое решение, и в действительности это фиктивное множество данных было получено с помощью генератора случайных чисел с нормальным распределением, доступного в системе. Специальным образом в данные были «введены» два ортогональных (независимых) фактора, по которым были сгенерированы корреляции между переменными. Этот пример факторного анализа воспроизводит два фактора такими, как они и были, (т.е. фактор удовлетворенности работой и фактор удовлетворенности домашней жизнью). Таким образом, если бы явление (а не искусственные, как в примере, данные) содержало эти два фактора, то вы, выделив их, могли бы кое-что узнать о скрытой или латентной структуре явления.
Другие результаты . Прежде, чем сделать окончательное заключение, дадим краткие комментарии к другим результатам.
Общности . Для получения общностей решения нажмите на кнопку Общности во вкладке Объясненная дисперсия диалогового окна Результаты факторного анализа. Вспомним, что общность переменной — это доля дисперсии, которая может быть воспроизведена при заданном числе факторов. Вращение факторного пространства не влияет на величину общности. Очень низкие общности для одной или двух переменных (из многих в анализе) могут указывать на то, что эти переменные не очень хорошо объяснены моделью.
Коэффициенты значений. Коэффициенты факторов могут быть использованы для вычисления значений факторов для каждого наблюдения. Сами коэффициенты представляет обычно малый интерес, однако факторные значения полезны при проведении дальнейшего анализа. Для отображения коэффициентов нажмите кнопку Коэффициенты значений факторов во вкладке Значения диалогового окна Результаты факторного анализа.
Значения факторов. Факторные значения могут рассматриваться как текущие значения для каждого опрашиваемого респондента (т.е. для каждого наблюдения исходной таблицы данных). Кнопка Значения факторов во вкладке Значения диалогового окна Результаты факторного анализа позволяет вычислить факторные значения. Эти значения можно сохранить для дальнейшего нажатием кнопки Сохранить значения.
Заключительный комментарий. Факторный анализ — это непростая процедура. Всякий, кто постоянно использует факторный анализ со многими (например, 50 или более) переменными, мог видеть множество примеров «патологического поведения», таких, как: отрицательные собственные значения и не интерпретируемые решения, особые матрицы и т.д. Если вы интересуетесь применением факторного анализа для определения или значащих факторов при большом числе переменных, вам следует тщательно изучить какое-либо подробное руководство (например, книгу Хармана (Harman, 1968)). Таким образом, так как многие критические решения в факторном анализе по своей природе субъективны (число факторов, метод вращения, интерпретация нагрузок), будьте готовы к тому, что требуется некоторый опыт, прежде чем вы почувствуете себя уверенным в нем. Модуль Факторный анализ был разработан специально для того, чтобы сделать легким для пользователя интерактивное переключение между различным числом факторов, вращениями и т.д., так чтобы испытать и сравнить различные решения.
Этот пример взят из справочной системы ППП STATISTICA фирмы StatSoft
Итак, имеем два значения – одно плановое, второе проектное (или базовое и отчетное) и имеем значения отклонения факторов. Задача: построить в Excel красивую диаграмму отображения этих факторов.
Рис.0. Окончательный результат.
Создаем в Excel таблицу, в которой у нас находятся необходимые данные (см.рис.1).
После этого разносим их следующим образом (рис.2)
Теперь подпишем столбцы – столбец I – Значение, далее – Основа, далее Влияние фактора (рис.3).
В качестве базовой диаграммы мы будем использовать либо гистограмму либо линейчатую с наполнением.
Рис.4. Используемые типы диаграмм
Теперь поясню на рис.5 что я имею в виду под основой – это такое значение некоторого ряда которое позволит построить нам диаграмму максимально точно.
В вычислении значений этого ряда поступаем следующим образом:
1. Значение первой основы (сразу после базового значения) принимаем равным либо базовому значению (если первый фактор имеет позитивное влияние) либо (базовое значение – величина влияния) – если фактор имеет негативное влияние.
2. Для последующих основ применяется та же схема. Если значение фактора положительное, то за основу берем результирующее значение, полученное на предыдущем факторе. Если же отрицательное, то берем (результирующее – абсолютное значение негативного фактора).
Что такое основа легко понять по рис.5.
Ту величину, которую я назвал “Влияние фактора” вычисляем как значение изменения фактора по модулю (абсолютное значение) с помощью функции ABS() – рис.6.
Рис.6. Вычисленные значения “Влияния фактора”
Для первой основы используются следующая функция:
ЕСЛИ(L6>0;I5;I5+L6) — т.е. если первый фактор больше нуля, то берем базовое значение, в противном случае берем базовое + значение изменения фактора (в нашем примере получается просто 100).
ЕСЛИ(L7>0;M6;M6+L7) — т.е. если фактор больше нуля, то берем полученное на предыдущем факторе результирующее значение, в противном случае берем базовое + значение изменения фактора.
Ахтунг! Не забывайте про правила сложения – если я говорю “плюс значение”, это значит, что подразумевается не абсолютное значение, а позитивное или негативное. Т.е. для третьего фактора получим следующую логику:
Значение изменения фактора меньше нуля, следовательно берем сумму предыдущего результирующего значения и значения изменения фактора, т.е. основа будет равна 170+(-30)=170-30=140.
Результирующее значение вычисляется по формуле:
ЕСЛИ(L6>0;J6+L6;J6) – т.е. если изменения фактора позитивное, то результирующим значением будет сумма предыдущего результирующего значения и величины изменения фактора, а в противном случае – просто значение основы. Далее переходим уже непосредственно к построению диаграммы. Выделяем ячейки от названия категорий до столбца “Влияние фактора” включительно.
И вставляем необходимый тип диаграммы (в данном случае – гистограмму).
Удаляем вертикальную ось, удаляем основные вертикальные и горизонтальные линии осей и у нас получается нечто вроде рис.9.
В свойствах горизонтальной оси также поставим “Нет линий” (рис.10).
Рис.10. Делаем ось невидимой
Далее добавляем рядам “Влияние фактора” и “Значение” подписи данных. Но получается маленькая нестыковка – даже в тех случаях, когда изменение фактора было отрицательным у нас выводятся положительные значения. Для этого дальше переходим обратно на лист 1 и выставляем соответственные форматы для позитивных и негативных значений.
Для негативных, соответственно: –0,0 – рис.11
Рис.11. Изменение формата чисел в столбце “Влияние фактора”.
Получившийся результат показан на рис.12
Рис.12. Подписи данных после изменения формата
Как видим, уже все изменения отображаются логически верно. Остался маленький штришок – находим точки ряда с негативным изменением и изменяем им цвет заливки на красный, а также меняем цвета подписей данных для этого ряда для большей наглядности (рис.13).
Рис.13. Окончательный результат.
Мы получили симпатичную диаграммку, которую не стыдно вставить в презентацию или в документ.
источник
Постановка задачи.
Каждое экономическое, общественное и физическое явление находится во взаимодействии с другими явлениями. При изучении связей рассматриваемых явлений выделяют независимые признаки  (факторные признаки) и результативные признаки
(факторные признаки) и результативные признаки  . Факторные признаки влияют на результативные признаки.
. Факторные признаки влияют на результативные признаки.
Зависимости между признаками подразделяются на две категории – функциональные и корреляционные.
При функциональных связях каждому значению фактора соответствует вполне определенное значение результативного признака:
Примером функциональной связи служит закон Ома:
При корреляционной связи результативный признак зависит как от факторного признака , так и других факторов 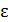 :
:
В экономических явлениях широко присутствуют корреляционные связи.
Так, на прибыльность банка влияют процентные ставки (факторный признак) и другие признаки – объемы операций, заработная плата сотрудников, затраты на оборудование и т.д. Влияние прочих факторов 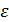 на результат может быть незначительным, умеренным или существенным.
на результат может быть незначительным, умеренным или существенным.
Методологию изучения статистической взаимосвязи рассмотрим на конкретном примере.
По семи областям проведено статистическое исследование по двум признакам: расходы на покупку продовольственных товаров в общих расходах и среднедневная заработная плата одного работающего. Каждый признак представлен выборкой из семи значений с целью уменьшения количества расчетов. Исследование выполнено случайным образом и его результаты отображены в таблице 1.1.
| № п/п | Среднедневная заработная плата одного работающего, тыс. руб., X | Расходы на покупку продовольственных товаров в общих расходах, %, Y |
| 45,1 | 68,8 | |
| 59,0 | 61,2 | |
| 57,2 | 59,9 | |
| 61,8 | 56,7 | |
| 58,8 | 55,0 | |
| 47,2 | 54,3 | |
| 55,2 | 49,3 |
Требуетсяпровести регрессионный и корреляционный анализ по двум выборкам для нахождения уравнения регрессии между двумя признаками. Уравнение регрессии позволит в дальнейшем формировать прогноз на будущее.
Выбор вида математической функции можно осуществить тремя методами: графическим, аналитическим и экспериментальным.
Построение графика зависимости результирующего признака от факторного .
Суть этапа заключается в построении зависимости результирующего признака от факторного на корреляционном поле (Рис.1). Порядок обозначения выборок через и обычно следует из условия задачи. Через семь точек на корреляционном поле можно попытаться провести аппроксимирующую функцию. Однако для маленьких выборок (меньше десяти) зачастую трудно установить вид зависимости признака от . Первый этап (построение графика) предполагает решение задачи на качественном уровне. Перейдем к количественному решению задачи.
Рисунок 1.1 – Корреляционное поле зависимости от
I – Линейная модель.
Цель этапа – установить уравнение связи двух переменных Y и X. Выберем простейшее линейное уравнение.
Линейное уравнение имеет вид y = a + bx. Для расчета коэффициентов а и b составим систему нормальных уравнений, полученных по методу наименьших квадратов-МНК:
По исходным данным задачи рассчитаем:  и их значения внесем в таблицу 1.2.
и их значения внесем в таблицу 1.2.
| Таблица 1.2 | ||||||||
| Линейная модель | ||||||||
| №п/п |  |  | 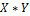 |  |  |  |  |  |
| 45,10 | 68,80 | 3102,88 | 2034,01 | 4733,44 | 61,10 | 7,71 | 11,20 | |
| 59,00 | 61,20 | 3610,80 | 3481,00 | 3745,44 | 56,23 | 4,97 | 8,12 | |
| 57,20 | 59,90 | 3426,28 | 3271,84 | 3588,01 | 56,86 | 3,04 | 5,08 | |
| 61,80 | 56,70 | 3504,06 | 3819,24 | 3214,89 | 55,25 | 1,45 | 2,56 | |
| 58,80 | 55,00 | 3234,00 | 3457,44 | 3025,00 | 56,30 | -1,30 | 2,36 | |
| 47,20 | 54,30 | 2562,96 | 2227,84 | 2948,49 | 60,36 | -6,06 | 11,16 | |
| 55,20 | 49,30 | 2721,36 | 3047,04 | 2430,49 | 57,56 | -8,26 | 16,75 | |
| Сумма | 384,30 | 405,20 | 22162,34 | 21338,41 | 23685,76 | 403,66 | 1,55 | 57,23 |
| Среднее значение | 54,90 | 57,89 | 3166,05 | 3048,34 | 3383,68 | — | — | 8,18 |
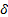 | 5,86 | 5,74 | — | — | — | — | — | — |
 | 34,33 | 32,92 | — | — | — | — | — | — |
Коэффициенты 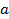 и
и  найдем из системы уравнений, например, путем подстановки, либо из дисперсионного анализа по формулам:
найдем из системы уравнений, например, путем подстановки, либо из дисперсионного анализа по формулам:
где, 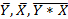 — средние значения,
— средние значения,
 — среднее квадратическое отклонение
— среднее квадратическое отклонение
Уравнение линейной регрессии примет окончательный вид:
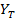 – теоретические значения, в отличие от Y – фактических значений, заданных по условию задачи.
– теоретические значения, в отличие от Y – фактических значений, заданных по условию задачи.
Теоретические значения будем получать из линейного уравнения путем подстановки фактических значений .
Экономический смысл коэффициента состоит в том, что с увеличением среднедневной заработной платы на 1 руб. доля расходов на покупку продовольственных товаров снижается в среднем на 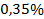 .
.
Найдем среднюю ошибку аппроксимации  .
.
Для нашей задачи выражено в процентах, поэтому:
Допустимый предел — не более 8-10%.
Таким образом, средняя ошибка аппроксимации почти вошла в допустимый предел.
Цель этапа – рассчитать линейный коэффициент корреляции и установить силу связи между и .
Линейный коэффициент корреляции найдем по формуле
где,  — среднее квадратическое отклонение по ,
— среднее квадратическое отклонение по ,
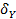 — среднее квадратическое отклонение по ,
— среднее квадратическое отклонение по ,
Значение 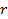 , взятое по модулю, сравниваем со шкалой Чеддока (Приложение 1). Связь умеренная и обратная, поскольку r имеет отрицательное значение.
, взятое по модулю, сравниваем со шкалой Чеддока (Приложение 1). Связь умеренная и обратная, поскольку r имеет отрицательное значение.
Определим коэффициент детерминации, который получим путем возведения коэффициента корреляции в квадрат.
Коэффициент детерминации также указывает на влияние фактора на результат .
Вариация результата на  объясняется вариацией фактора .
объясняется вариацией фактора .
Оценка значимости уравнения регрессии.
Оценка значимости уравнения регрессии проводится с помощью F-критерия Фишера. Выдвигается гипотеза  — фактор
— фактор  не оказывает влияния на результат . При этом коэффициент регрессии равен нулю,
не оказывает влияния на результат . При этом коэффициент регрессии равен нулю, 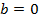 .
.
Процесс оценки нулевой гипотезы сводится к сравнению фактического 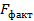 и табличного
и табличного  значения критерия Фишера. Если
значения критерия Фишера. Если 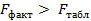 , то нулевая гипотеза не отклоняется. Признается факт существования зависимости результата от
, то нулевая гипотеза не отклоняется. Признается факт существования зависимости результата от  так и для генеральных совокупностей Y и X.
так и для генеральных совокупностей Y и X.
Уравнение регрессии значимо.
Если  , то нулевая гипотеза не отклоняется, но признается статистическая незначимость, ненадежность зависимости от . Уравнение регрессии незначимо, ненадежно. В этом случае требуется подбор другого уравнения регрессии.
, то нулевая гипотеза не отклоняется, но признается статистическая незначимость, ненадежность зависимости от . Уравнение регрессии незначимо, ненадежно. В этом случае требуется подбор другого уравнения регрессии.
Для линейной модели равно:
где – коэффициент корреляции,
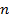 – число показателей выборки.
– число показателей выборки.
вычисляют следующим образом:
1. Определяем К1, которое равно количеству факторов . В однофакторной модели  , в двухфакторной
, в двухфакторной 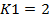 . В нашей задаче модель однофакторная, поэтому
. В нашей задаче модель однофакторная, поэтому 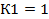 .
.
2. Определяем 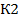 , которое рассчитываем по формуле
, которое рассчитываем по формуле 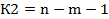 , где – число значений выборки,
, где – число значений выборки,  – количество факторов. Для однофакторной модели
– количество факторов. Для однофакторной модели 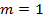 . Для рассматриваемой задачи
. Для рассматриваемой задачи 
3. На пересечении столбца  и
и  находят
находят  по таблице Фишера с уровнем значимости
по таблице Фишера с уровнем значимости  (Приложение 2). Уровень значимости
(Приложение 2). Уровень значимости 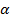 — это вероятность отвергнуть гипотезу .
— это вероятность отвергнуть гипотезу .
Следовательно, уравнение регрессии незначимо, ненадежно. Требуется подбор другого уравнения, например, одного из нелинейных.
II – Нелинейная модель
Предположим теперь, что результирующий фактор от факторного признака изменяется нелинейным образом. В качестве нелинейных моделей используют функции: степенную, показательную, экспоненциальную, гиперболическую. Для малых выборок, когда картина зависимости от просматривается плохо, требуется проверка всех моделей, а затем выбор наилучшей.
Выберем гиперболическую модель для уменьшения количества расчетов.
Уравнение равносторонней гиперболы 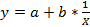
Для определение параметров и этого уравнения используется система нормальных уравнений по критерию метода наименьших квадратов:
Чтобы определить параметры уравнения гиперболы, необходимо привести ее к линейному виду. Для этого сделаем замену переменной 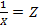 и получим систему уравнений:
и получим систему уравнений:
По исходным данным рассчитаем  и внесем их в таблицу 1.3.
и внесем их в таблицу 1.3.
| таблица 1.3 | ||||||||||
| Нелинейная модель | ||||||||||
| №п/п |  |  |  |  | 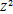 |  |  | 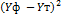 | 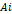 |  |
| 45,10 | 68,80 | 0,02 | 1,53 | 0,000492 | 4733,44 | 61,82 | 48,71 | 10,14 | 119,12 | |
| 59,00 | 61,20 | 0,02 | 1,04 | 0,000287 | 3745,44 | 56,31 | 23,90 | 7,99 | 10,98 | |
| 57,20 | 59,90 | 0,02 | 1,05 | 0,000306 | 3588,01 | 56,87 | 9,16 | 5,05 | 4,06 | |
| 61,80 | 56,70 | 0,02 | 0,92 | 0,000262 | 3214,89 | 55,50 | 1,44 | 2,11 | 1,41 | |
| 58,80 | 55,00 | 0,02 | 0,94 | 0,000289 | 3025,00 | 56,37 | 1,88 | 2,49 | 8,33 | |
| 47,20 | 54,30 | 0,02 | 1,15 | 0,000449 | 2948,49 | 60,78 | 41,99 | 11,93 | 12,86 | |
| 55,20 | 49,30 | 0,02 | 0,89 | 0,000328 | 2430,49 | 57,54 | 67,93 | 16,72 | 73,71 | |
| Сумма | 384,30 | 405,20 | 0,13 | 7,51 | 0,002413 | 23685,76 | 405,20 | 195,01 | 56,45 | 230,47 |
| Сред знач | 54,90 | 57,89 | 0,02 | 1,07 | 0,000345 | 3383,68 | 27,86 | 8,06 | 32,92 | |
| δ | 5,86 | 5,74 | 0,002134 | |||||||
| δ^2 | 34,33 | 32,92 | 0,000005 |
Примечание. Значения Z рассчитываем до 4-го знака после запятой.
Коэффициенты и определим по формулам:
где, 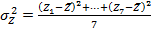
Уравнение гиперболы примет вид:
Здесь 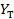 — теоретическое значение, — фактическое (по условию задачи) значение.
— теоретическое значение, — фактическое (по условию задачи) значение.
Качество гиперболической модели определяет средняя ошибка аппроксимации:
Качество построения модели оценивается как хорошее, если  не превышает
не превышает 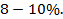 Ошибка аппроксимации входят в допустимый предел.
Ошибка аппроксимации входят в допустимый предел.
Сила связи между результативным признаком и факторным для нелинейной модели определяется индексом корреляции, в то время как у линейной модели – коэффициентом корреляции.
Связь между признаками и умеренная.
Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака характеризует индекс детерминации 
Вариация результата на 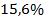 объясняется вариацией фактора
объясняется вариацией фактора 
Дата добавления: 2016-12-29 ; просмотров: 1098 | Нарушение авторских прав
источник