Расчет параметров уравнения линейной регрессии, проверку их статистической значимости и построения интервальных оценок можно выполнить значительно быстрее автоматически при использовании Пакета анализа Excel (программа «Регрессия»)
Пусть исходные данные примера 2.1 (расходы на питание – личный доход) представлены в Excel.
Выбираем команду Анализ данных→Регрессия.
В диалоговом окне режимаРегрессиязадаются следующие параметры:
® Входной интервал У– вводится ссылка на ячейки, содержащие данные по результативному признаку.
® Входной интервал Х – вводится ссылка на ячейки, содержащие факторные признаки.
® Метки – установите флажок в активное состояние, если выделены и заголовки столбцов.
® Константа- ноль – установите флажок в активное состояние, если оцениваете регрессионное уравнение без свободного члена.
При необходимости задаются и другие параметры.
Результаты расчетов с использованием инструмента Регрессия выводятся под общим названием Вывод итоговв виде следующих таблиц.
| Регрессионная статистика | |
| Множественный R | 0,952 |
| R- квадрат | 0,907 |
| Нормированный R- квадрат | 0,875 |
| Стандартная ошибка | 1,817 |
| Наблюдения |
| Дисперсионный анализ | ||||
| df | SS | MS | F | Значимость F |
| Регрессия | 96,1 | 96,1 | 29,12 | 0,01247 |
| Остаток | 9,9 | 3,3 | ||
| Итого |
| Коэффи- циенты | Стандартная ошибка | t-статис- тика | P- зна- чение | Нижнее 95% | Верхние 95% | |
| Y – пересеч. | -1,75 | 1,65 | -1,06 | 0,36669 | -7,001 | 3,501 |
| X | 0,775 | 0,14361 | 5,40 | 0,01247 | 0,318 | 1,232 |
Результаты работы программы «Регрессия» полностью совпадают с полученными ранее расчетами.
При необходимости выводятся предсказанные значения  результативного признака и значения остатков.
результативного признака и значения остатков.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное у | Остатки |
| -0,2 | 1,2 | |
| 2,9 | -0,9 | |
| -2 | ||
| 9,1 | 1,9 | |
| 12,2 | -0,2 |
Коэффициенты регрессии, их стандартные ошибки и коэффициент детерминации составляют:
a= -1,75; b=0,775;  = 1,65;
= 1,65;  =0,143;
=0,143;  = 0,907
= 0,907
Результаты регрессионного анализа принято записывать в виде:
ȳ= -1,75+0,775х ; = 0,907,
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Статическая значимость коэффициента  = 0,907 устанавливается поF – тесту. Поскольку ЗначимостьF= 0,0124
= 0,907 устанавливается поF – тесту. Поскольку ЗначимостьF= 0,0124
Обычно проверка значимости коэффициента а не производится. Оценим статистическую значимость коэффициентаb.
Поскольку P – значение = 0,0124
Оценим статистическую значимость коэффициента b. Поскольку Р – значение = 0,000158 2 — коэффициент детерминированности;
sey — стандартная ошибка для оценки y;
F — F-статистика, используемая для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df — степени свободы, используемые для нахождения F-критических значений в статистической таблице (для определения уровня надежности модели нужно сравнить значения в таблице с F-статистикой функции ЛИНЕЙН);
ssreg — регрессионая сумма квадратов;
ssresid — остаточная сумма квадратов.
Характеристики выводятся на экран дисплея в виде приведенного ниже массива (таблицы):
| mn | mn-1 | … | m2 | m1 | b |
| sen | Sen-1 | … | se2 | se1 | seb |
| r 2 | Seу | … | |||
| F | Df | … | |||
| ssreg | ssresid | … |
Порядок выполнения расчетов следующий:
1. Вводятся исходные данные или открывается существующий файл, содержащий исходные данные.
2. В рабочем окне Excel выделяется диапазон ячеек 5*(n+1) (5 число строк, (n+1) — число столбцов, n – число показателей факторов) для вывода результатов расчета.
3. Активизируются «Мастер функций» любым из способов:
а) в главном меню выбирается Вставка/Функция;
б) на панели инструментов Стандартная нажимается кнопка (fx)

4. В появившемся окне «Мастер функций шаг 1 из 2» среди категорий выбирается Статистические, среди функций — ЛИНЕЙН шаг 1 из 2 (рис. 3.1.1)
Рис. 3. 1. 1. Диалоговое окно «Мастер функций шаг 1 из 2»
5. В появившемся втором окне «Мастер функций» (рис. 3. 1. 2)
вводятся аргументы, т.е. указываются диапазоны ячеек рабочего окна EXCEL, в которых находятся исходные данные для У и Х, а также значения аргументов константа и статистика.
Рис. 3. 1. 2. Второе диалоговое окно «Мастер функций»
Рис. 3. 1. 3. Результат вычисления функции ЛИНЕЙН
6. Нажимается кнопка ОК. В выделенном диапазоне рабочего окна
Excel появляется результат — численное значение для коэффициента регрессии (b). Чтобы вывести всю статистику следует нажать клавишу , а затем — комбинацию клавиш + + .
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Да какие ж вы математики, если запаролиться нормально не можете. 8511 —  | 7378 —
| 7378 —  или читать все.
или читать все.
193.124.117.139 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
источник
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».

Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».
Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Отблагодарите автора, поделитесь статьей в социальных сетях.
источник
Если вам нужно разработать сложные статистические или инженерные анализы, вы можете сэкономить этапы и время с помощью пакета анализа. Вы предоставляете данные и параметры для каждого анализа, и в этом средстве используются соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые инструменты создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопку Анализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
Если вы используете Excel 2007, нажмите кнопку Microsoft Office  и выберите пункт Параметры Excel .
и выберите пункт Параметры Excel .
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
Примечание: Чтобы включить функцию Visual Basic для приложений (VBA) для пакета анализа, вы можете загрузить надстройку «пакет анализа — VBA» таким же образом, как и при загрузке пакета анализа. В диалоговом окне Доступные надстройки установите флажок Пакет анализа — VBA .
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Это средство выполняет простой анализ дисперсии для данных двух или более образцов. Анализ — это проверка гипотезы о том, что каждый образец выводится из того же основного распределения вероятности, что и для альтернативной гипотезы, для которой базовые распределения вероятностей не одинаковы. Если есть только два примера, вы можете использовать функцию на листе T . Проверка. В более чем двух выборках нет удобной обобщения с T .И может быть вызвана модель однофакторного дисперсионный проверки.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий , имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений , используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар превышает влияние отдельно удобрения и отдельно температуры.
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров из предыдущего примера).
На листе КОРРЕЛ и Пирсон рассчитываются коэффициент корреляции между двумя переменными измерения, если измерения для каждой переменной отображаются для каждого из N субъектов. (Отсутствие наблюдения для какой-либо из тем приводит к тому, что эта тема пропускается в анализе.) Средство анализа корреляции особенно полезно, если для N тем используется более двух переменных измерения. Она предоставляет выходную таблицу, матрицу корреляции, которая показывает значение КОРРЕЛ (или Пирсона), примененное к каждой возможной паре переменных измерения.
Коэффициент корреляции, например Ковариация, — это мера экстента, в котором одновременно различаются две переменные измерения. В отличие от ковариации коэффициент корреляции масштабируется таким образом, чтобы его значение не зависело от единиц, в которых выражаются две переменные измерения. (Например, если две переменные измерения являются весом и высотой, значение коэффициента корреляции не меняется, если вес конвертируется из килограммов в килограммы). Значение любого коэффициента корреляции должно находиться в диапазоне от-1 до + 1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Вы можете использовать инструменты корреляции и ковариации в одном и том же параметре, если у вас есть N различных переменных измерения, которые потратили на набор отдельных пользователей. Средства корреляции и ковариации предоставляют выходную таблицу, матрицу, которая показывает коэффициент корреляции или ковариацию соответственно между каждой парой переменных измерения. Разница заключается в том, что коэффициенты корреляции масштабируются в зависимости от-1 и + 1 включительно. Соответствующие ковариации не масштабируются. Как коэффициент корреляции, так и ковариация — это величины экстентов, в которых две переменные различны друг от друга.
Инструмент Ковариация вычисляет значение функции КОвариация на листе. P для каждой пары переменных измерения. (Прямое использование ковариации. Функция P вместо средства Ковариация является разумной альтернативой, если есть только две переменные измерения, т. е. N = 2.) Запись по диагонали в выходной таблице инструмента ковариации в строке i — это Ковариация переменной измерения i-ой. Это всего лишь дисперсия Генеральной совокупности для этой переменной, вычисленная функцией на листе var . P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f 1, «P(F
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
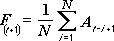
N — число предшествующих периодов, входящих в скользящее среднее;
A j — фактическое значение в момент времени j;
F j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Инструмент «ранжирование и персентиль» формирует таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. Вы можете проанализировать относительные значения в наборе данных. Это средство использует функции ранжирования на листе. EQ и ПРОЦЕНТРАНГ. INC. Если вы хотите учитывать привязанные значения, используйте ранг. EQ , который обрабатывает привязанные значения в соответствии с одинаковым рангом или использует ранг.Функция AVG , возвращающая среднее значение ранга для привязанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Средство регрессия использует функцию листа ЛИНЕЙН.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
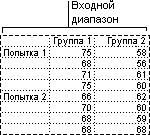
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t =0 «P(T Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
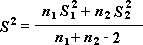
Двухвыборочный t-тест с одинаковыми дисперсиями
Это средство анализа выполняет двухвыборочный t-тест учащегося. В этой форме t-тест предполагается, что два набора данных получены из распространения с одинаковыми дисперсиями. Она называется гомоскедастическийм t-тестом. Вы можете использовать этот t-тест, чтобы определить, могут ли два примера быть получены из распределений с одинаковым заполнением.
Двухвыборочный t-тест с различными дисперсиями
Это средство анализа выполняет двухвыборочный t-тест учащегося. В этой форме t-тест предполагается, что два набора данных получены из распространения с неравными дисперсиями. Она называется гетероскедастическийм t-тестом. Как и в предыдущем случае с одинаковыми дисперсиями, вы можете использовать этот t-тест, чтобы определить, должны ли два примера поступать из распределения с одинаковым заполнением. Используйте этот тест, если в двух примерах есть отдельные темы. Используйте парный тест, описанный в приведенном ниже примере, когда есть один набор тем, а в двух образцах — измерения для каждой темы до и после обработки.
Для определения тестовой величины t используется следующая формула.
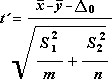
Следующая формула используется для вычисления степеней свободы, DF. Так как результат вычисления обычно не является целым числом, значение df округляется до ближайшего целого числа, чтобы получить критическое значение из t-таблицы. Функция листа Excel — T . Тест использует вычисляемое значение DF без округля, так как можно вычислить значение для T . Проверка с нецелочисленной DF. Из-за разных подходов к определению степеней свободы результаты в T . Тестирование и это средство t-тест будет отличаться в случае неравной вариации.
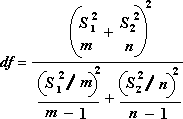
Двухвыборочный z-тест для средних — это Двухвыборочный z-тест для средних и известных отклонений. Это средство используется для проверки гипотезы на то, что в двух или двусторонних вариантах есть различия между двумя единицами заполнения. Если вариативность неизвестна, то функция листа Z .Вместо этого следует использовать проверку .
При использовании этого инструмента следует внимательно просматривать результат. «P(Z = ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z = ABS(z) или Z
Вы всегда можете задать вопрос специалисту Excel Tech Community, попросить помощи в сообществе Answers community, а также предложить новую функцию или улучшение на веб-сайте Excel User Voice.
источник
Проведем множественный регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа.
Эффективно использовать надстройку Пакет анализа могут только пользователи знакомые с теорией множественного регрессионного анализа.
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить регрессионный анализ с помощью надстройки Пакет анализа (инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой;
- Даны комментарии обо всех показателях, рассчитанных надстройкой, и приведены ссылки на соответствующие разделы статей, посвященные простой линейной регрессии.
В надстройке Пакет анализа для построения линейной регрессионной модели (как простой, так и множественной) имеется специальный инструмент Регрессия.
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
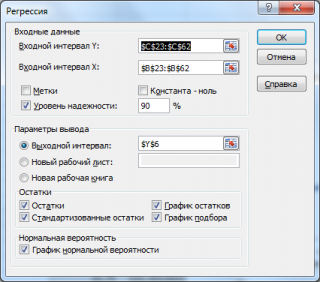
- Входной интервалY: ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки);
- Входной интервал Х: ссылка на значения переменных Х (нужно указать все столбцы со значениями Х). Ссылку рекомендуется делать на диапазон с заголовками (в окне не забудьте установить галочку Метки);
- Константа-ноль: если галочка установлена, то надстройка подбирает плоскость регрессии с b=0;
- Уровень надежности: Это значение используется для построения доверительных интервалов для наклона и сдвига. Уровень надежности = 1- альфа. Если галочка не установлена или установлена, но уровень значимости = 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а уровень надежности отличен от 95%, то рассчитываются 2 доверительных интервала: один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
- Остатки: будут вычислены остатки модели, т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
- Стандартизированные остатки: Вышеуказанные значения остатков будут поделены на значение их стандартного отклонения;
- График остатков: Для каждой переменной Xj будет построена точечная диаграмма: значения остатков и соответствующее значение Хji (при прогнозировании на основании значений 2-х переменных Х будет построено 2 диаграммы (j=1 и 2));
- График подбора: Для каждой переменной Xj будут построены точечные диаграммы с двумя рядами данных: точки данных (Xji;Yi) и (Xji;Yiпредсказанное);
- График нормальной вероятности: Будет построена точечная диаграмма с названием График нормального распределения. По сути — это график значений переменной Y, отсортированных по возрастанию.
В результате вычислений будет заполнен указанный Выходной интервал.
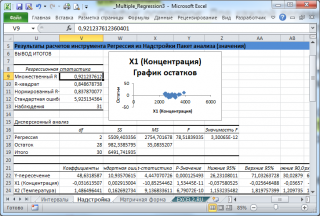
Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка , столбцы I:T).
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про множественную линейную регрессию с помощью функций ЛИНЕЙН() , ТЕНДЕНЦИЯ() и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
- Множественный R. В случае множественной линейной регрессии — это квадратный корень из коэффициента детерминации R 2
- R-квадрат. В случае множественной линейной регрессии – это коэффициент детерминации R 2
- Нормированный R-квадрат. Подробнее см. здесь (англ. термин Adjusted R-squared)
- Стандартная ошибка. Подробнее см. здесь;
- Наблюдения. Количество значений Y.
- df – степени свободы (Degrees of Freedom).
- SS – сумма квадратов (Sum of Squares)
- MS – SS/df (MSR и MSE)
- F – значение статистики F (MSR/MSE)
- ЗначимостьF – p-значение, функция F.РАСП.ПХ()
источник
Пакет анализа — это надстройка Excel, которая представляет широкие возможности для проведения статистического анализа. Установка средств Пакет анализа
В стандартной конфигурации программы Excel вы не найдете средства Пакет анализа. Это средство надо установить в качестве надстройки Excel. Для этого выполните следующие действия:
Выберите команду Сервис => Надстройки.
В диалоговом окне Надстройки (рис. 12) установите флажок Пакет анализа.
В результате выполненных действий в нижней части меню Сервис появится новая команда Анализ данных. Эта команда предоставляет доступ к средствам анализа, которые есть в Excel.
Рис. 12. Диалоговое окно Надстройки
Продемонстрируем возможности Пакета программ на следующем примере.
Построим модель объема реализации одного из продуктов фирмы.
Объем реализации — это зависимая переменная Y. В качестве независимых, объясняющих переменных выбраны:
Статистические данные по всем переменным приведены в табл. 5.
В рассматриваемом примере число наблюдений п = 16, факторных признаков т = 5.
Использование инструмента Корреляция
Для проведения корреляционного анализа нужно выполнить следующие действия:
1) расположить данные в смежных диапазонах ячеек;
2) выбрать команду Сервис => Анализ данных (рис. 13). Появится диалоговое окно Анализ данных (рис. 14);
Рис.13. Выбор команды Анализ данных
3)в диалоговом окне Анализ данных выбрать инструмент Корреляция (рис.14), щелкнуть по кнопке ОК. Появится диалоговое окно Корреляция (рис.15);
Рис.14. Выбор команды Анализ данных
4)в диалоговом окне Корреляция в поле «Входной интервал» необходимо ввести диапазон ячеек, содержащих исходные данные. Если также выделены заголовки столбцов, то установить флажок «Метки в первой строке» (рис.15);
5) выбрать параметры вывода. В данном примере — установить переключатель «Новый рабочий лист»;
Рис.15. Диалоговое окно Корреляция
На новом рабочем листе получаем результаты вычислений- таблицу значений коэффициентов парной корреляции(рис.16).
Рис.16. Результаты корреляционного анализа
Анализ матрицы коэффициентов парной корреляции показывает, что зависимая переменная, т.е. объем реализации, имеет тесную связь:
что свидетельствует о наличии коллинеарости. Из этих двух переменных оставим в модели Х5 — индекс расходов. Переменные X1 (время), X3 (цена изделия) и Х4 (цена отрасли) также исключаем из модели, т.к. связь их с результативным признаком Y (объемом реализации) невысокая.
После исключения незначимых факторов имеем п=16,k = 2. Модель приобретает вид:
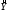 = ао+а1Х2+а2Х5.
= ао+а1Х2+а2Х5.
На основе метода наименьших квадратов проведем оценку параметров регрессии по формуле (3). При этом используем данные, приведенные в табл.6.
Непосредственное вычисление (вычисление «вручную») вектора оценок параметров регрессии а согласно формуле (3) весьма громоздко, т.к. матрица независимых переменных X имеет довольно высокую размерность (16 х 3), матрица Y- размерности (16 х 1). В табл. 7 приведены размерности матриц — результатов промежуточных действий.
Задача существенно упрощается при использовании средств Excel. Операции, предписанные формулой (3) целесообразно проводить с помощью следующих встроенных в Excel функций:
•ТРАНСП — транспонирование матриц,
•МОБР — вычисление обратной матрицы.
Для вычисления вектора оценок параметров регрессии а в Excel необходимо выполнить следующие действия:
Выделить диапазон ячеек для записи вектора а, соответствующий его размерности (3×1) (рис. 16).
Используя встроенные в Excel функции, ввести формулу (3), определяющую вектор а.
Нажать одновременно клавиши CTRL + SHIFT + ENTER. Появится результат (рис. 17).
Рис. 16. Выделение диапазона ячеек (3 х 1) для записи вектора оценок параметров регрессии а
Уравнение регрессии зависимости объема реализации от затрат на рекламу и индекса потребительских расходов можно записать в виде:
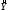 = -1471,3143 + 9,5684*Х2+15,7529*Х5.
= -1471,3143 + 9,5684*Х2+15,7529*Х5.
Рис. 17. Результат вычислений — вектор оценок параметров регрессии а
Расчетные значения Y определяются путем последовательной подстановки в эту модель значений факторов, взятых для каждого момента времени t.
Применение инструмента Регрессия
Для проведения регрессионного анализа с помощью Excel выполните следующие действия:
выберите команду Сервис => Анализ данных;
в диалоговом окне Анализ данных выберите инструмент Регрессия. Щелкните по кнопке ОК;
в диалоговом окне Регрессия в поле «Входной интервал F» введите адрес диапазона ячеек, который представляет зависимую переменную Y. В поле «Входной интервал X» введите адреса одного или нескольких диапазонов, которые содержат значения независимых переменных (в рассматриваемом примере — переменные Х2, Х5). Если выделены заголовки столбцов, то установить флажок «Метки в первой строке»;
выберите параметры вывода. В данном примере – установите переключатель «Новая рабочая книга»;
в поле «Остатки» поставьте необходимые флажки;
Результаты представлены на рис. 18 и заключены в таблицах.
Пояснения к таблице «Регрессионная статистика» (рис. 18)
Наименования в отчете Excel
Коэффициент множественной корреляции, индекс корреляции
Коэффициент детерминации, R 2
Рис. 18. Результаты регрессионного анализа, проведенного с помощью Excel
Пояснения к таблице «Дисперсионный анализ» (рис. 18)
Df — число степеней свободы
Во втором столбце таблицы дисперсионного анализа (рис. 18) содержатся коэффициенты уравнения регрессии а, а1а2, в третьем столбце содержатся стандартные ошибки коэффициентов уравнения регрессии, в четвертом — F-статистика, используемая для проверки значимости коэффициентов уравнения регрессии.
В таблице «Вывод остатка» (рис. 18) приведены вычисленные по модели значения 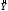 и значения остаточной компоненты е.
и значения остаточной компоненты е.
Исследование на наличие автокорреляции остатков проведем с помощью d-критерия Дарбина — Уотсона. Для определения величины d-критерия воспользуемся расчетной таблицей 7.
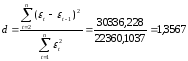 .
.
В качестве критических табличных уровней при п = 16, двух объясняющих факторах при уровне значимости = 0,05 возьмем величины вdL = 0,98 и dU=1,54 (приложения А и Б). Расчетное значение d = 1,3567 попало в интервал от dL= 0,98 до dU =1,54 (рис.20)
Рис. 20. Сравнение расчетного значения d-критерия Дарбина -Уотсона с критическими значениями вdL и dU
Так как расчетное значение d-критерия Дарбина-Уотсона попало в зону неопределенности, то нельзя сделать окончательный вывод об автокорреляции остатков по этому критерию.
Для определения степени автокорреляции вычислим коэффициент автокорреляции и проверим его значимость при помощи критерия стандартной ошибки. Стандартная ошибка коэффициента корреляции рассчитывается по формуле:
Коэффициенты автокорреляции случайных данных должны обладать выборочным распределением, приближающимся к нормальному с нулевым математическим ожиданием и средним квадратическим отклонением, равным
Если коэффициент автокорреляции первого порядка r1 находится в интервале
по которой построен прогноз на два шага вперед, причем прогнозные значения на 17-ый и 18-ый периоды соответственно составляют:
Х5(17) = 97,008+1,739*17-0,0488*17 2 = 112,4678,
Описанным выше способом (п. 1.3) построим линию тренда для временного ряда «Расходы на материалы» (рис. 20).
Рис. 20. Результат построения тренда и прогнозирования по тренду для временного ряда «Расходы на материал»
Для фактора Х2 «затраты на материал» выбираем полиномиальную модель пятой степени (этой модели соответствует наибольшее значение коэффициента детерминации):
Х2= -0,00055157*t 5 + 0,02915029*t 4 — 0,55145744 *t 3 + 4,31897327*t 2 — 11,61564797*t + 12,83076923.
Замечание. Полиномы высоких порядков редко используются при прогнозировании экономических показателей. В этом случае при вычислении прогнозных оценок коэффициентов модели необходимо учитывать большое число знаков после запятой.
Прогнозные значения на 17-ый и 18-ый периоды соответственно составляют:
Для получения прогнозных оценок переменной 7 по модели
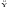 =-1471,3143 + 9,5684*X2+15,7529*X5
=-1471,3143 + 9,5684*X2+15,7529*X5
подставим в нее найденные прогнозные значения факторов Х2 и Х5, получим:
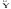 (17) =-1471,3143 + 9,5684*5,7485 + 15,7529*112,4678 = 355,3805,
(17) =-1471,3143 + 9,5684*5,7485 + 15,7529*112,4678 = 355,3805,
 (18) = -1471,3143 + 9,5684*4,8485 + 15,7529*112,4988 = 347,2573.
(18) = -1471,3143 + 9,5684*4,8485 + 15,7529*112,4988 = 347,2573.
Доверительный интервал прогноза имеет границы:
верхняя граница прогноза: 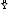 (n+l) + U(l),
(n+l) + U(l),
нижняя граница прогноза: 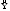 (n+l) — U(l),
(n+l) — U(l),
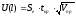 , Vпр=XпрT (X T X) -1 Xпр.
, Vпр=XпрT (X T X) -1 Xпр.
 ,
,
tкр=2,16 (по таблице при =0,05 и числе степеней свободы 13),
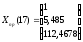 ,
, 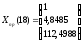 .
.
Тогда с использованием Excel , имеем
U(1)=41,473*2,16* =42,9714
=42,9714
U(2)=41,473*2,16*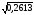 =45,7964.
=45,7964.
Результаты прогнозных оценок модели регрессии представим в таблице прогнозов (табл. 8).
источник
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».
Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
На практике эти две методики часто применяются вместе.

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
источник
Представляем вашему вниманию статистический метод расчета справедливой стоимости акций. Речь идет о регрессионном анализе. Незаменимую помощь в процессе исследования окажет обычный Excel.
Что такое регрессия
Регрессионный анализ является статистическим методом исследования. Он позволяет оценить зависимость одной (зависимой) переменной от других (независимых) переменных. Самой простой является линейная регрессия. Ее формула такова:
где Y — зависимая переменная,
x — независимые переменные, влияющие на нее,
a — коэффициенты регрессии.
Зависимой переменной может выступать цена актива. Возможные влияющие факторы — цены других активов, финансовые и макропоказатели и т.д. В нашем случае считать будем теоретическую (расчетную) условно справедливую стоимость акций, зависящую от цен на другие активы.
Важно, чтобы независимых переменных было не слишком мало, но и не слишком много. Влияющие переменные стоит отбирать из экономических соображений, руководствуясь здравым смыслом. В идеале их нужно тестировать на мультиколлинеарность и т.д., но наш обзор посвящен базовым принципам регрессионного анализа. Статистическую значимость модели поможет оценить показатель R2 (R — квадрат), о нем речь пойдет дальше.
Если фактическая цена бумаги заметно отклоняется от расчетной, появляется повод для дополнительного анализа. Стоит также смотреть на техническую картину, мультипликаторы, общерыночную ситуацию. Существуют также методы финансового моделирования, носящие фундаментальный подход, в частности, модели дисконтирования денежных потоков (DCF) и модели дисконтирования дивидендов (DDM).
Пример расчетов в Excel и выводы
В качестве примера возьмем акции американского нефтегазового гиганта Exxon Mobil (XOM). Модель будет упрощенной и учебной и не является рекомендацией для осуществления операций с бумагами, ситуацию нужно смотреть в комплексе.
Независимыми переменными у нас выступят фьючерсы на американскую нефть WTI (склеенные фронтальные контракты) и индекс S&P 500. Логика проста — бизнес компании зависит от цен на нефть, а поведение акций в теории должно быть связано в общерыночной ситуацией.
Шаг 1. Выкачиваем в Excel котировки XOM, SPX и CL1. Данные возьмем за пять лет. Так как на более длительных периодах наблюдалась разная структурная ситуация на нефтяном рынке. Возьмем статистику в недельной разбивке, будет 262 наблюдения.
Шаг 2. Активируем настройку регрессионного анализа. Открываем раздел Файл. Переходим на вкладку Параметры Excel — Надстройки. Внизу появившегося окна будет вкладка Управление, где стоит параметр Надстройки Excel, жмем — Перейти.
Выбираем опцию Пакет анализа.
Готово. Результат появится в разделе Данные — Анализ данных.
Шаг 3. Строим регрессию. При клике на Анализ данных появится меню с опциями функционала для анализа. Выбираем Регрессия.
Заполняем окна по аналогии со схемой, используя ранее выгруженные данные по активам.
На выходе получаем вот такие данные.
Шаг 4. Интерпретация. Статистических показателей много. Не вдаваясь в теорию, наиболее интересными являются значения коэффициентов регрессии и показатель R2.
Наша модель будет иметь следующий вид:
Цена акций Exxon Mobil = $96,2 + 0,28*WTI — 0,01*S&P 500
R — квадрат равен 0,61. Показатель показывает, насколько значение зависимой переменной определяется значениями независимых переменных. Речь идет о статистической значимости модели. Модель является очень хорошей, если R2 превышает 0,8, и при этом сама модель имеет экономическое обоснование. В нашем случае все не настолько идеально, но все же выше 0,5, поэтому модель можно использовать.
Отмечу, что в процессе подготовки материала делались расчеты не только за пять лет, но и за 10, и за три года, также WTI заменялась на Brent. Итоговый вариант был выбран в связи с наибольшим значением R2.
Шаг 5. Применение. Рассчитаем в Excel теоретические значения акций Exxon за весь использовавшийся для построения модели период (5 лет).
Построим линейную диаграмму, на которой будут представлены динамика фактической цены и расчетной цены акций. Заметно, что расхождения между двумя величинами редко носили слишком серьезный характер. По состоянию на 06.06.2019 фактическая цена акций составила $74,2, а теоретическая — $76,7. Исходя из этого, критерия бумаги вполне справедливо оценены рынком. Однако это только один, причем упрощенный подход. Ситуацию нужно рассматривать в комплексе. К примеру, медианный таргет аналитиков на 12 месяцев равен $84. Это усредненный показатель результатов моделей фундаментальной оценки, предполагающий заметный потенциал роста.
Корреляционный анализ
Дополним нашу регрессию корреляционным анализом. Корреляция означает зависимость одного показателя от другого. Коэффициент корреляции — показатель взаимосвязи (в нашем случае финансовых активов).
Строим корреляционную матрицу. В том же разделе Анализ данных выбираем опцию Корреляция. Заполняем окно, как показано ниже, с учетом котировок наших активов.
На выходе получаем корреляционную матрицу. На ней видно, что цена Exxon положительно связана с WTI (коэффициент корреляции = 0,55) и отрицательно зависит от динамики индекса S&P 500 (коэффициент корреляции = -0,48).
Так что Exxon — это преимущественно нефтяная история, зачастую не совпадающая по динамике с широким рынком. Это можно заметить на графике трех активов с 2010 г. Ситуация стала такой с 2014 г., когда рынок нефти обвалился из-за структурных сдвигов. На нашей выборке за 5 лет корреляция между WTI и S&P 500 равна 0,13, то есть несущественна.
Построение графика простой регрессии
Расскажем об еще одном регрессионном функционале Excel. Программа позволяет построить график линейной регрессии. Правда доступно это лишь при наличии одной независимой переменной. В нашем случае ею будет нефть, так как она в большей мере объясняет движения акций Exxon — коэффициент регрессии равен 0,28 против (-0,01) у S&P 500.
Строим точечную диаграмму по XOM и WTI за 5 лет. Получаем поле корреляции. Щелкаем по любой из точек на диаграмме и меню левой кнопки мыши выбираем Добавить линию тренда.
В окне выбираем линейную линию тренда, ставим галочки напротив Показывать уравнение и Поместить на диаграмму R2.
В итоге получим такую схему зависимости Exxon (y) от WTI (x). В нашем случае модель не является статистически значимой — R-квадрат равен лишь 0,3.
Как еще использовать корреляционно-регрессионный анализ
В архивах раздела Обучение БКС Экспресс есть материалы на эту тему.
Отмечу, что наш материал носил ознакомительный характер. В регрессионные модели можно вносить макроэкономические, финансовые и прочие показатели. В идеале, независимые переменные нужно тестировать на ряд факторов. Наш обзор — это пример «мгновенной и грубой» оценки. В любом случае, выводы, полученные в результате регрессионного моделирования, стоит комбинировать с другими подходами к инвестиционному анализу.
Адрес для вопросов и предложений по сайту: website4@bcs.ru
Copyright © 2008–2019. ООО «Компания БКС» . г. Москва, Проспект Мира, д. 69, стр. 1
Все права защищены. Любое использование материалов сайта без разрешения запрещено.
Лицензия на осуществление брокерской деятельности № 154-04434-100000 , выдана ФКЦБ РФ 10.01.2001 г.
Данные являются биржевой информацией, обладателем (собственником) которой является ПАО Московская Биржа. Распространение, трансляция или иное предоставление биржевой информации третьим лицам возможно исключительно в порядке и на условиях, предусмотренных порядком использования биржевой информации, предоставляемой ОАО Московская Биржа. ООО «Компания Брокеркредитсервис» , лицензия № 154-04434-100000 от 10.01.2001 на осуществление брокерской деятельности. Выдана ФСФР. Без ограничения срока действия.
* Материалы, представленные в данном разделе, не являются индивидуальными инвестиционными рекомендациями. Финансовые инструменты либо операции, упомянутые в данном разделе, могут не подходить Вам, не соответствовать Вашему инвестиционному профилю, финансовому положению, опыту инвестиций, знаниям, инвестиционным целям, отношению к риску и доходности. Определение соответствия финансового инструмента либо операции инвестиционным целям, инвестиционному горизонту и толерантности к риску является задачей инвестора. ООО «Компания БКС» не несет ответственности за возможные убытки инвестора в случае совершения операций, либо инвестирования в финансовые инструменты, упомянутые в данном разделе.
Информация не может рассматриваться как публичная оферта, предложение или приглашение приобрести, или продать какие-либо ценные бумаги, иные финансовые инструменты, совершить с ними сделки. Информация не может рассматриваться в качестве гарантий или обещаний в будущем доходности вложений, уровня риска, размера издержек, безубыточности инвестиций. Результат инвестирования в прошлом не определяет дохода в будущем. Не является рекламой ценных бумаг. Перед принятием инвестиционного решения Инвестору необходимо самостоятельно оценить экономические риски и выгоды, налоговые, юридические, бухгалтерские последствия заключения сделки, свою готовность и возможность принять такие риски. Клиент также несет расходы на оплату брокерских и депозитарных услуг, подачи поручений по телефону, иные расходы, подлежащие оплате клиентом. Полный список тарифов ООО «Компания БКС» приведен в приложении № 11 к Регламенту оказания услуг на рынке ценных бумаг ООО «Компания БКС». Перед совершением сделок вам также необходимо ознакомиться с: уведомлением о рисках, связанных с осуществлением операций на рынке ценных бумаг; информацией о рисках клиента, связанных с совершением сделок с неполным покрытием, возникновением непокрытых позиций, временно непокрытых позиций; заявлением, раскрывающим риски, связанные с проведением операций на рынке фьючерсных контрактов, форвардных контрактов и опционов; декларацией о рисках, связанных с приобретением иностранных ценных бумаг.
Приведенная информация и мнения составлены на основе публичных источников, которые признаны надежными, однако за достоверность предоставленной информации ООО «Компания БКС» ответственности не несёт. Приведенная информация и мнения формируются различными экспертами, в том числе независимыми, и мнение по одной и той же ситуации может кардинально различаться даже среди экспертов БКС. Принимая во внимание вышесказанное, не следует полагаться исключительно на представленные материалы в ущерб проведению независимого анализа. ООО «Компания БКС» и её аффилированные лица и сотрудники не несут ответственности за использование данной информации, за прямой или косвенный ущерб, наступивший вследствие использования данной информации, а также за ее достоверность.
источник